Most real-world problems are big enough that you can't just head for the end goal, you have to break them down into smaller parts and set up intermediate goals. For that matter, most games are that way too. “Win” is too big a goal in chess, so you might have a subgoal like don't get forked. While creating subgoals makes intractable problems tractable, it also creates the problem of determining the relative priority of different subgoals and whether or not a subgoal is relevant to the ultimate goal at all. In chess, there are libraries worth of books written on just that.
And chess is really simple compared to a lot of real world problems. 64 squares. 32 pieces. Pretty much any analog problem you can think of contains more state than chess, and so do a lot of discrete problems. Chess is also relatively simple because you can directly measure whether or not you succeeded (won). Many real-world problems have the additional problem of not being able to measure your goal directly.
IQ & Early Childhood Education
In 1962, what's now known as the Perry Preschool Study started in Ypsilanti, a blue-collar town near Detroit. It was a randomized trial, resulting in students getting either no preschool or two years of free preschool. After two years, students in the preschool group showed a 15 point bump in IQ scores; other early education studies showed similar results.
In the 60s, these promising early results spurred the creation of Head Start, a large scale preschool program designed to help economically disadvantaged children. Initial results from Head Start were also promising; children in the program got a 10 point IQ boost.
The next set of results was disappointing. By age 10, the difference in test scores and IQ between the trial and control groups wasn't statistically significant. The much larger scale Head Start study showed similar results; the authors of the first major analysis of Head Start concluded that
(1) Summer programs are ineffective in producing lasting gains in affective and cognitive development, (2) full-year programs are ineffective in aiding affective development and only marginally effective in producing lasting cognitive gains, (3) all Head Start children are still considerably below national norms on tests of language development and scholastic achievement, while school readiness at grade one approaches the national norm, and (4) parents of Head Start children voiced strong approval of the program. Thus, while full-year Head Start is somewhat superior to summer Head Start, neither could be described as satisfactory.
Education in the U.S. isn't cheap, and these early negative results caused calls for reductions in funding and even the abolishment of the program. Turns out, it's quite difficult to cut funding for a program designed to help disadvantaged children, and the program lives on despite repeated calls to cripple or kill the program.
Well after the initial calls to shut down Head Start, long-term results started coming in from the Perry preschool study. As adults, people in the experimental (preschool) group were less likely to have been arrested, less likely to have spent time in prison, and more likely to have graduated from high school. Unfortunately, due to methodological problems in the study design, it's not 100% clear where these effects come from. Although the goal was to do a randomized trial, the experimental design necessitated home visits for the experimental group. As a result, children in the experimental group whose mothers were employed swapped groups with children in the control group whose mothers were unemployed. The positive effects on the preschool group could have been caused by having at-home mothers. Since the Head Start studies weren't randomized and using instrumental variables (IVs) to tease out causation in “natural experiments” didn't become trendy until relatively recently, it took a long time to get plausible causal results from Head Start.
The goal of analyses with an instrumental variable is to extract causation, the same way you'd be able to in a randomized trial. A classic example is determining the effect of putting kids into school a year earlier or later. Some kids naturally start school a year earlier or later, but there are all sorts of factors that can cause that happen, which means that a correlation between an increased likelihood of playing college sports in kids who started school a year later could just as easily be from the other factors that caused kids to start a year later as it could be from actually starting school a year later.
However, date of birth can be used as an instrumental variable that isn't correlated with those other factors. For each school district, there's an arbitrary cutoff that causes kids on one side of the cutoff to start school a year later than kids on the other side. With the not-unreasonable assumption that being born one day later doesn't cause kids to be better athletes in college, you can see if starting school a year later seems to have a causal effect on the probability of playing sports in college.
Now, back to Head Start. One IV analysis used a funding discontinuity across counties to generate a quasi experiment. The idea is that there are discrete jumps in the level of Head Start funding across regions that are caused by variations in a continuous variable, which gives you something like a randomized trial. Moving 20 feet across the county line doesn't change much about kids or families, but it moves kids into an area with a significant change in Head Start funding.
The results of other IV analyses on Head Start are similar. Improvements in test scores faded out over time, but there were significant long-term effects on graduation rate (high school and college), crime rate, health outcomes, and other variables that are more important than test scores.
There's no single piece of incredibly convincing evidence. The randomized trial has methodological problems, and IV analyses nearly always leave some lingering questions, but the weight of the evidence indicates that even though scores on standardized tests, including IQ tests, aren't improved by early education programs, people's lives are substantially improved by early education programs. However, if you look at the early commentary on programs like Head Start, there's no acknowledgment that intermediate targets like IQ scores might not perfectly correlate with life outcomes. Instead you see declarations like “poor children have been so badly damaged in infancy by their lower-class environment that Head Start cannot make much difference”.
The funny thing about all this is that it's well known that IQ doesn't correlate perfectly to outcomes. In the range of environments that you see in typical U.S. families, to correlation to outcomes you might actually care about has an r value in the range of .3 to .4. That's incredibly strong for something in the social sciences, but even that incredibly strong statement is a statement IQ isn't responsible for "most" of the effect on real outcomes, even ignoring possible confounding factors.
Cholesterol & Myocardial Infarction
There's a long history of population studies showing a correlation between cholesterol levels and an increased risk of heart attack. A number of early studies found that lifestyle interventions that made cholesterol levels more favorable also decreased heart attack risk. And then statins were invented. Compared to older drugs, statins make cholesterol levels dramatically better and have a large effect on risk of heart attack.
Prior to the invention of statins, the standard intervention was a combination of diet and pre-statin drugs. There's a lot of literature on this; here's one typical review that finds, in randomized trials, a combination of dietary changes and drugs has a modest effect on both cholesterol levels and heart attack risk.
Given that narrative, it certainly sounds reasonable to try to develop new drugs that improve cholesterol levels, but when Pfizer spent $800 million doing exactly that, developing torcetrapib, they found that they created a drug which substantially increased heart attack risk despite improving cholesterol levels. Hoffman-La Roche's attempt fared a bit better because it improved cholesterol without killing anyone, but it still failed to decrease heart attack risk. Merck and Tricor have also had the same problem.
What happened? Some interventions that affected cholesterol levels also affected real health outcomes, prompting people to develop drugs that affect cholesterol. But it turns out that improving cholesterol isn't an inherent good, and like many intermediate targets, it's possible to improve without affecting the end goal.
99%-ile Latency & Latency
It's pretty common to see latency measurements and benchmarks nowadays. It's well understood that poor latency in applications costs you money, as it causes people to stop using the application. It's also well understood that average latency (mean, median, or mode), by itself, isn't a great metric. It's common to use 99%-ile, 99.9%-ile, 99.99%-ile, etc., in order to capture some information about the distribution and make sure that bad cases aren't too bad.
What happens when you use the 99%-iles as intermediate targets? If you require 99%-ile latency to be under 0.5 millisec and 99.99% to be under 5 millisecond you might get a latency distribution that looks something like this.
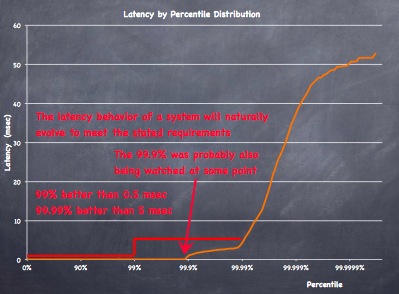
This is a graph of an actual application that Gil Tene has been showing off in his talks about latency. If you specify goals in terms of 99%-ile, 99.9%-ile, and 99.99%-ile, you'll optimize your system to barely hit those goals. Those optimizations will often push other latencies around, resulting in a funny looking distribution that has kinks at those points, with latency that's often nearly as bad as possible everywhere else.
It's is a bit odd, but there's nothing sinister about this. If you try a series of optimizations while doing nothing but looking at three numbers, you'll choose optimizations that improve those three numbers, even if they make the rest of the distribution much worse. In this case, latency rapidly degrades above the 99.99%-ile because the people optimizing literally had no idea how much worse they were making the 99.991%-ile when making changes. It's like the video game solving AI that presses pause before its character is about to get killed, because pausing the game prevents its health from decreasing. If you have very narrow optimization goals, and your measurements don't give you any visibility into anything else, everything but your optimization goals is going to get thrown out the window.
Since the end goal is usually to improve the user experience and not just optimize three specific points on the distribution, targeting a few points instead of using some kind of weighted integral can easily cause anti-optimizations that degrade the actual user experience, while producing great slideware.
In addition to the problem of optimizing just the 99%-ile to the detriment of everything else, there's the question of how to measure the 99%-ile. One method of measuring latency, used by multiple commonly used benchmarking frameworks, is to do something equivalent to
for (int i = 0; i < NUM; ++i) {
auto a = get_time();
do_operation();
auto b = get_time();
measurements[i] = b - a;
}
If you optimize the 99%-ile of that measurement, you're optimizing the 99%-ile for when all of your users get together and decide to use your app sequentially, coordinating so that no one requests anything until the previous user is finished.
Consider a contrived case where you measure for 20 seconds. For the first 10 seconds, each response takes 1ms. For the 2nd 10 seconds, the system is stalled, so the last request takes 10 seconds, resulting in 10,000 measurements of 1ms and 1 measurement of 10s. With these measurements, the 99%-ile is 1ms, as is the 99.9%-ile, for the matter. Everything looks great!
But if you consider a “real” system where users just submit requests, uniformly at random, the 75%-ile latency should be >= 5 seconds because if any query comes during the 2nd half, it will get jammed up, for an average of 5 seconds and as much as 10 seconds, in addition to whatever queuing happens because requests get stuck behind other requests.
If this example sounds contrived, it is; if you'd prefer a real world example, see this post by Nitsan Wakart, which finds shows how YCSB (Yahoo Cloud Serving Benchmark) has this problem, and how different the distributions look before and after the fix.
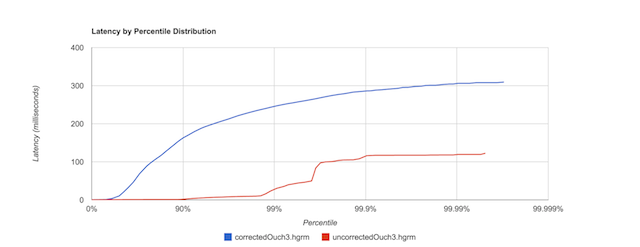
The red line is YCSB's claimed latency. The blue line is what the latency looks like after Wakart fixed the coordination problem. There's more than an order of magnitude difference between the original YCSB measurement and Wakart's corrected version.
It's important to not only consider the whole distribution, to make make sure you're measuring a distribution that's relevant. Real users, which can be anything from a human clicking something on a web app, to an app that's waiting for an RPC, aren't going to coordinate to make sure they don't submit overlapping requests; they're not even going to obey a uniform random distribution.
Conclusion
This is the point in a blog post where you're supposed to get the one weird trick that solves your problem. But the only trick is that there is no trick, that you have to constantly check that your map is somehow connected to the territory.
Resources
1990 HHS Report on Head Start. 2012 Review of Evidence on Head Start.
A short article on instrumental variables. A book on econometrics and instrumental variables.
Aysylu Greenberg video on benchmarking pitfalls; it's not latency specific, but it covers a wide variety of common errors. Gil Tene video on latency; covers many more topics than this post. Nitsan Wakart on measuring latency; has code examples and links to libraries.
Acknowledgments
Thanks to Leah Hanson for extensive comments on this, and to Scott Feeney and Kyle Littler for comments that resulted in minor edits.